在学习Elastic Search的时候注意到,当我们去索引一个指定id的新文档时请求用PUT方式,如
1 | PUT /website/blog/123 |
而索引一个自动分配id的新文档时就使用POST方式,如
1 | POST /website/blog/ |
同样是新建一个文档,为什么要使用不同的方式呢?
在学习Elastic Search的时候注意到,当我们去索引一个指定id的新文档时请求用PUT方式,如
1 | PUT /website/blog/123 |
而索引一个自动分配id的新文档时就使用POST方式,如
1 | POST /website/blog/ |
同样是新建一个文档,为什么要使用不同的方式呢?
上一篇博客运行了例子wordCount,用Hadoop来做词频统计,流程是这样的:
1)先用HDFS的命令行工具,将要统计的文件(假设很大,1000G)复制到HDFS上;
2)用Java写MapReduce代码,写完后调试编译,然后打包成Jar包;
3)执行Hadoop命令,用这个Jar包在Hadoop集群上处理1000G的文件,然后将结果文件存放到指定的目录。
4)用HDFS的命令行工具查看处理结果文件。
操作系统:macOS Mojave OS 10.14.1
虚拟机:VMware-Fusion-11.0.2
Linux: ubuntu-18.04.1-desktop-amd64.iso 64位
本文是在mac上用VMware装Linux虚拟机,搭建了伪分布式,也就是所有节点运行在同一个机器上,也可以同时安装多个虚拟机,来搭建完全分布式。
有些情景不一定需要元素全部有序,而是需要每次处理键值最大的元素,如手机运行程序,程序有优先级,来电的优先级比游戏程序的优先级高。
这是就适合优先队列数据结构。优先队列的主要操作有 删除最大元素delMax()和插入元素insert()。高效地实现优先队列具有挑战性,我们可以基于二叉堆来实现优先队列。
通过插入一系列元素,然后一个个删除其中最小的元素合一实现排序算法,堆排序就是基于堆的优先队列的实现。
HashMap也是一个储存价值对的常用方法,她的底层由哈希表实现(数组),用拉链法解决哈希碰撞(链表)。
它继承于AbstractMap,实现了Map<K,V>, Cloneable, Serializable接口。
jdk1.8引入了红黑树,来解决链表长度过长导致的查询速度下降问题,当碰撞过多,链表过长,这时我们将链表用红黑树来替代,以降低查询效率,所以在hashMap中同时有链表节点(Node)的结构,也有树节点(TreeNode)的结构
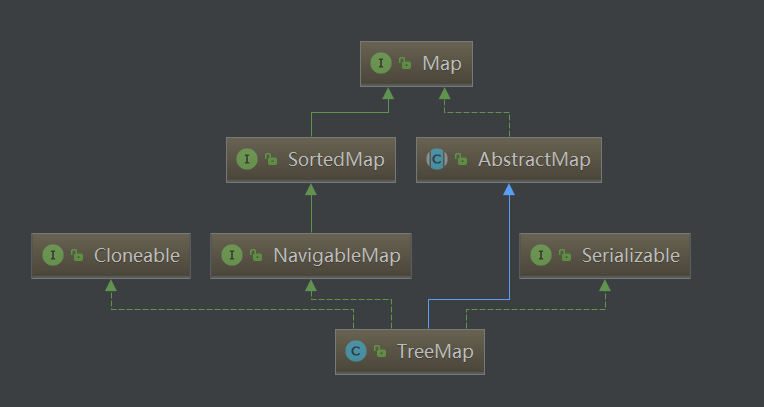
TreeMap 继承于AbstractMap,实现了navigableMap, treeMap是红黑树的java实现,已经分析过,红黑树能保证树的增删改查都在O(logN).