Java集合是我么最经常使用的工具,我们称这些集合类为容器,和数组的不同: 数组长度固定,集合类长度可变,数组存放基本类型,集合类存放对象的引用。
常用集合: List, Set, Map。
Collection UML: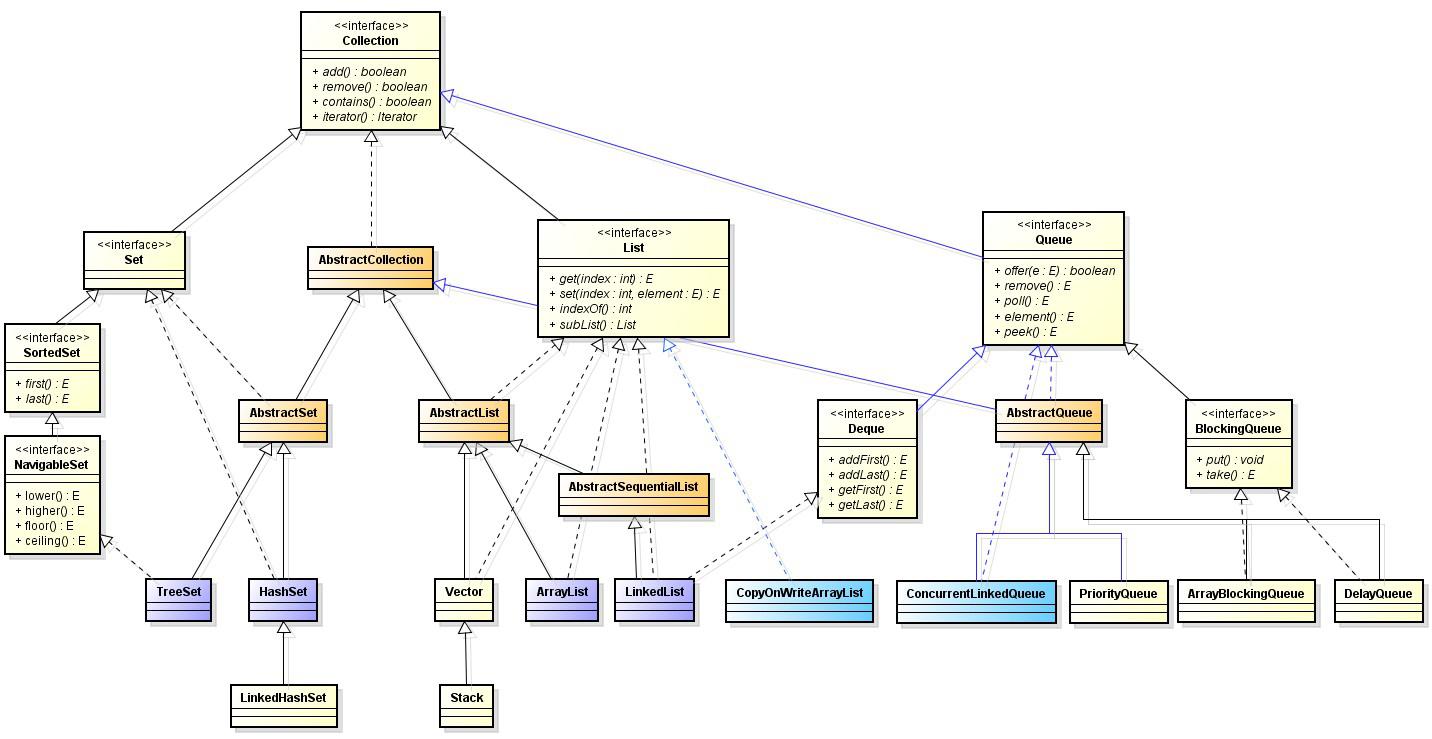
要学习Collection,除了数据结构基础之外还要有Iterable概念
Iterable
Iterable接口为高效遍历更多的数据结构提供了支持。
常见的循环方式:
for 循环:
1 | for (int i = 0, len = strings.size(); i < len; i++) { |
foreach循环
1 | for (String var : strings) { |
Iterator循环
1 | Iterator iterator = strings.iterator(); |
for循环针对数组这种可以直接取下标的类型,foreach则主要对类似链表的结构提供遍历支持,链表没有下标,所以使用for循环遍历会大大降低性能。Iterator实际上就是foreach。
但是什么样的集合可以用foreach遍历,怎么让对象支持foreach遍历就需要了解Iterator迭代器,迭代器为JAVA集合类对象提供foreach遍历的支持(只能向前不能退后)。
让一个对象实现foreach遍历需要实现Iterable/Iterator接口
Iterator接口的声明
1 | public interface Iterator<E> { |
Iterable接口的声明
1 | public interface Iterable<T> { |
这两个接口不合二为一的原因是:一个实现了Iterable接口的类可以实现多个Iterator内部类,如一个向前迭代器一个向后迭代器。
Iterator还有一个子接口,是为需要双向遍历数据时准备的,在后续分析ArrayList和LinkedList时都会看到它。它主要增加了以下几个方法:
1 | // 是否有前一个元素 |
Collection
接口可以继承,List、Queue和Set接口继承于Collection接口,所以Collection是一个超级接口,他直接继承于Iterable接口,所以所有的Collection集合类都能实现foreach循环。
Collection也是面向接口编程的典范,通过它可以在多种实现类间转换,这也是面向对象编程的魅力之一。
Collection提供了一些方便操作集合的方法
1 | //返回集合的长度,如果长度大于Integer.MAX_VALUE,返回Integer.MAX_VALUE |
Collection 接口有一个超级实现类AbstractCollection,为了减少实现类所需要实现的借口方法。
List
List接口的一些不同于Collection的方法:
1 | //在指定位置,将指定的集合插入到当前的集合中 |
相应的,她也有一个超级实现类AbstractList。
ArrayList
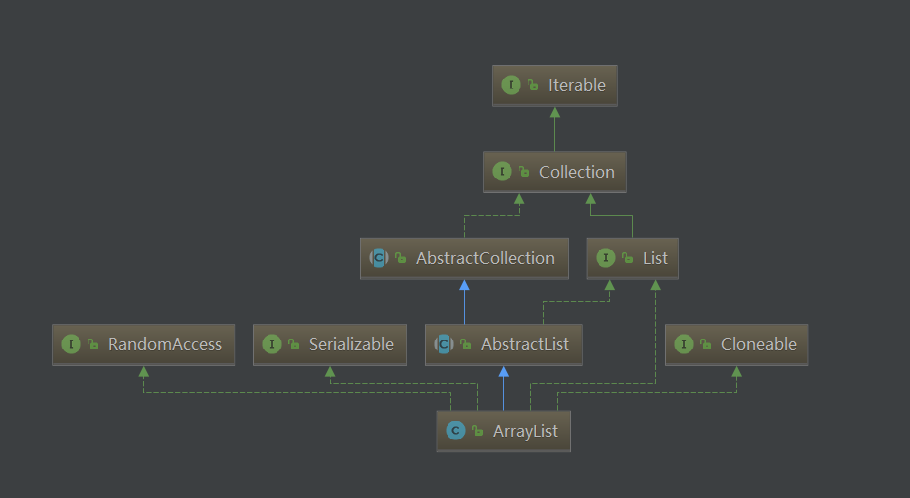
直接继承于AbstractList超级类,并实现了List接口,RandomAccess接口支持随机访问,Cloneable表示实现类支持克隆,具体表现为重写了clone方法,java.io.Serializable则表示支持序列化,如果需要对此过程自定义,可以重写writeObject与readObject方法
ArrayList其实是用数组实现的,是但是他是Resizable-array implementation of the <tt>List</tt> interface.就是说它可以动态的改变数组大小。为了实现这一点,需要有复制的过程,如声明一个大小为5的ArrayList(有参构造函数),前五个数据插入无序改变数组大小,若要继续添加元素,需要将数组扩容,声明一个更大容量的数组,将前五个元素复制再进行新的添加。这样的结构在数组元素很大时性能快速下降,但是有实现优化措施。接下来会进行研究
成员变量
1 | //这是一个用来标记存储容量的数组,也是存放实际数据的数组。 |
构造函数
有参构造函数:
- 参数为初始容量,生成一个大小为initialCapacity的类型为Object的数组,参数小于0抛出非法参数异常。
- 参数是一个集合c,从另一个集合来构造, 调用toArray方法复制给elementData。
1 | public ArrayList(int initialCapacity) { |
无参构造函数:初始化为空数组{},当插入第一个参数时数组大小会扩充为默认值:10
1 | public ArrayList() { |
方法
1 | public int size() { |
增删改查和获取
1 | //查 |
增删涉及数组大小变化
1 | //增 |
至此整个扩容过程结束。首先创建一个空数组elementData,第一次插入数据时直接扩充至10,然后如果elementData的长度不足,就扩充1.5倍,如果扩充完还不够,就使用需要的长度作为elementData的长度。
但是数据量很大的时候还是会频繁拷贝影响性能,所以如果数据相较大可以用有参构造函数直接声明一个大容量的ArrayList,但是这样会一直占用较大内存。
我们也可以在添加元素之前提前根据添加操作次数扩容,来减少拷贝次数,且可以不用一直占用大内存。
1 | public void ensureCapacity(int minCapacity) { |
删除:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//删除某个下标的元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);//把index之后的内容复制到index之前的元素的后边。
elementData[--size] = null; // clear to let GC do its work
//数组长度-1,让垃圾回收机制收回
return oldValue;
}
结论: 了解了ArrayList的原理之后明白他实际上是用数组实现,虽然可以动态改变大小,但是改变大小由于需要进行拷贝所以是耗费性能的,虽然她的扩容机制已经做了优化(每次扩容1.5倍,减少拷贝次数),但是还是要根据情况使用,比如数据量大且对内存不做要求时可以在实例化的时候一步到位声明大数组,若对内存有要求可以根据业务需要在添加操作之前扩充足够的容量。
ArrayList还是和数组一样,更适合于数据随机访问,而不太适合于大量的插入与删除
了解了底层机制才能更好的使用,提高程序效率和内存使用,不踩坑
参考:https://www.jianshu.com/p/407afb4a267a
线程安全-ArrayList vs Vector
ArrayList是非线程安全的,Vector是线程安全的;HashMap是非线程安全的,HashTable是线程安全的;StringBuilder是非线程安全的,StringBuffer是线程安全的。
线程安全
当多个线程类并发操作某类的某个方法,(在该方法内部)来修改这个类的某个成员变量的值,不会出错,则我们就说,该的这个方法是线程安全的。
某类的某方法是否线程安全的关键是:
(1) 该方法是否修改该类的成员变量(有没有数据共享);
(2) 是否给该方法加锁(是否用synchronized关键字修饰),在调用该方法的过程中别的线程的调用无法执行
线程不安全
当多个线程类并发操作某类的某个方法,(在该方法内部)来修改这个类的某个成员变量的值,很容易就会发生错误,故我们就说,这个方法是线程不安全的。如果要把这个方法变成线程安全的,则用 synchronized关键字来修饰该方法即可。
当1线程正在使用或修改某个成员变量(共享数据),但是这个过程中线程2将该变量修改,那么线程1的执行结果会受到影响。
但是用synchronized进行同步控制影响了这个方法的效率,要慎重使用这个关键字
ArrayList, Vector
ArrayList是线程不安全的,Vector是线程安全的,如果需要多线程操作同一个对象,就需要用Vector,否则ArrayList有更高的效率。
但并不是非线程安全的就一定不安全,只有当不同线程操作同一个对象时才会有可能发生错误,如果每个线程都new一个ArrayList就不会发生这样的问题了。
modCount
经常看到类的成员变量modCount
修改次数modCount,这个变量记录了对象的修改次数,再Iterator中使用,Iterator中有变量expectedModCount也记录了对象的更改次数,在遍历的时候若expectedModCount和modCount不同则说明有其他线程已经修改了这个对象,抛出异常。
modCount通常在线程不安全的类中才会看到,是一个避免多线程操作错误的方式:fast-fail策略。所以当大家遍历那些非线程安全的数据结构时,尽量使用迭代器。