数据库索引其实是一种数据结构,将数据库的主键(或其他索引)用一定的数据结构存储,便于对数据库进行查找。
已经了解了常用的查找算法和相关数据结构,数据库中索引常用的数据结构有哈希表或B-树,B+树。
为什么使用索引
计算机一般包含两种类型的存储,计算机主存(RAM)和外部存储器(硬盘,CD等)。主存的容量小,读取速度快,外部存储则相反。通常数据库文件都十分大,不能全部放在主存中,只能在访问的时候去外部存储器中查找,这就回产生IO操作。
一般来说索引本身也比较大,往往以索引文件的形式存储在外部存储器上,查找索引的过程也会产生IO消耗。IO操作的读取数据花费时间有 磁盘的寻道时间(磁臂移动到指定的磁道),旋转延迟(磁盘转速相关),传输时间三个部分。这样的时间相对于CUP的执行速度已经非常缓慢了。
所以索引的存在主要为了减少对磁盘的读取。比如我们要找主键在98-100之间的数据,没有索引我们只能从表头开始查找全部的数据来找到这三个数据,产生大量的IO操作,但是如果建立的索引可能只需要几次就够了。
同时根据局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。预读的长度一般为页(page)的整倍数。
页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
数据库索大多用树来实现,hash虽然检索效率非常高,但是存在一些缺点:只能进行等式比较,不能范围查找,也不能使用like这样的模糊查找。而且由于hash值和原来的键值并不相同,所以不能用hash索引优化排序。
B树
同时在设计索引的数据结构的时候也需要尽量减少IO操作。我们很容易想到用二叉树来进行LogN级别的查找,但是我们进行IO操作的次数由二叉树的高度决定。因此我们可以考虑将查找树变得“矮胖”,让高度变得更低,以减少IO操作。
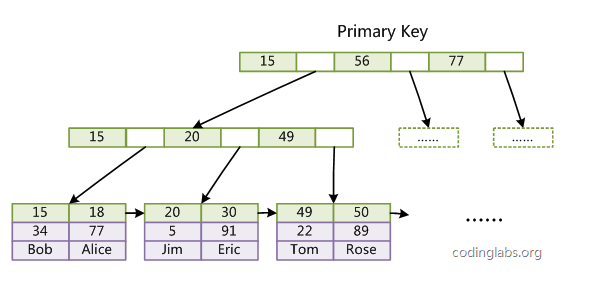
B树是一种多路平衡查找树。利用局部性原理,我们把每个节点的大小世界设为一个页的大小,每个节点最多包含k个孩子,k取决于磁盘页的大小。这样可以保证每个节点只需要一次IO操作就可以被全部读入内存。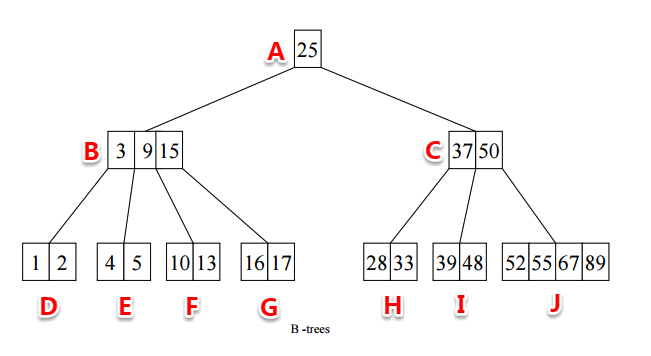
B树的比较次数并不比二叉树少,但是相比IO速度,内存中比较的耗时几乎可以忽略。所以减少IO操作就可以提高性能。
B树主要应用于问价系统以及部分数据库索引,如MongoDB,MongoDB 这类 nosql 适用于数据模型简单,性能要求高的场合。
更详细的操作删除操作不做分析。
漫画说话:查看
B+树
B+树是B树的一种变体,有更高的查询性能,因为相比B树它更加“矮胖”。
B+树的非叶子节点都不保存数据妹纸用来保存索引,这样每一层可以保存更多的索引,让树更矮。叶子节点保存所有的数据。而且叶子节点之间有指向兄弟的指针,所以所有叶子其实是一个链表。
而且,每个副节点的元素都会出现在子节点中,是子节点中最大(或最小的元素)。这一条原理保证了叶子节点里有所有的元素,并形成了一个有序链表。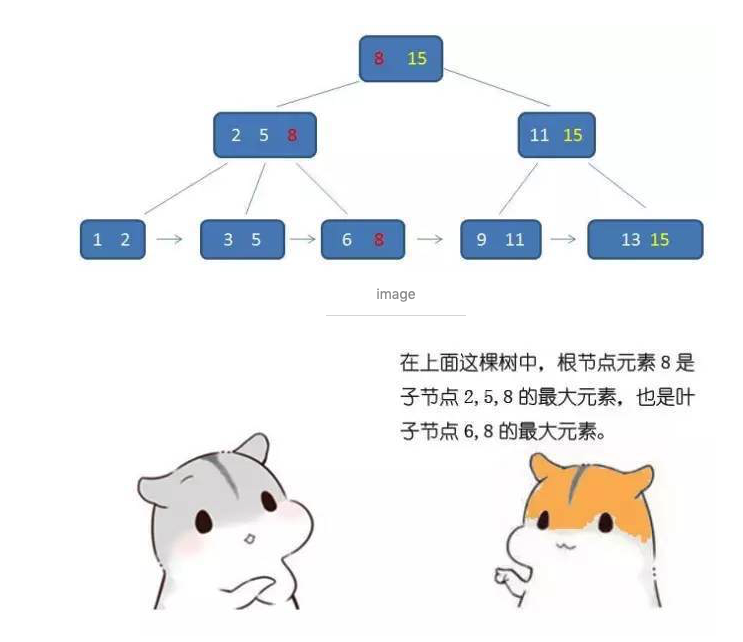
B+树不仅更加“矮胖”,而且对范围查找更加高效,只需要在链表上做遍历即可。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
漫画说话:查看
B树和B+树的插入和删除都比较复杂,所以不要过多创建索引, 权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也需要进行调整重建
聚集索引 非聚集索引
聚集索引,在索引页里直接存放数据,而非聚集索引在索引页里存放的是索引,这些索引指向专门的数据页的数据。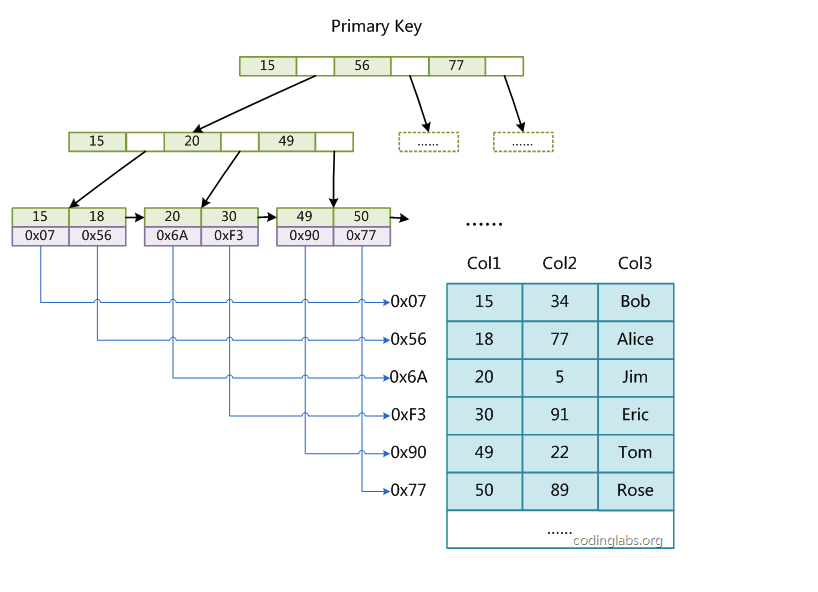
mySQL使用非聚集索引。非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置,非聚集索引检索效率比聚集索引低,但对数据更新影响较小,因为数据的物理存储不按照索引排序。MySQL使用非聚集索引
聚集索引的特点是表数据文件本身就是索引文件,直接包含了数据信息而不是数据的地址。聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较大,因为数据的物理排列顺序和索引一致。聚集索引不适用于频繁更改的列。InnoSQL使用聚集索引