操作系统:macOS Mojave OS 10.14.1
虚拟机:VMware-Fusion-11.0.2
Linux: ubuntu-18.04.1-desktop-amd64.iso 64位
本文是在mac上用VMware装Linux虚拟机,搭建了伪分布式,也就是所有节点运行在同一个机器上,也可以同时安装多个虚拟机,来搭建完全分布式。
安装JDK
下载jdk并解压
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
1 | sudo mkdir /usr/java |
设置环境变量
1 | sudo vim /etc/profile |
粘贴如下内容
1 | #set java environment |
使其生效
1 | jiaxuehui@ubuntu:/usr/java$ source /etc/profile |
设置ssh免密服务
ssh免密可以让服务器之间通信无阻,Hadoop集群是DataNode与DataNode之间的文件传输、在Hadoop的启动过程中,需要登录到其他机器的sbin目录下执行一些文件的时候需要用到ssh登录.
1 | #安装ssh服务 |
安装hadoop
下载压缩包http://mirrors.ircam.fr/pub/apache/hadoop/common/stable/
解压到/home/jiaxuehui/hadoop
1 | tar -xvf hadoop-2.9.2.tar |
将如下内容添加到环境变量之后
1 | export HADOOP_HOME=/home/jiaxuehui/hadoop/hadoop-2.9.2 |
输入hadoop version出现如下输出
配置Hadoop中相应的文件(伪分布式)
要配置的文件都在/home/jiaxuehui/hadoop/hadoop-2.9.2/etc/hadoop下。
伪分布式就是用一个机器同时运行NameNode,SecondaryNameNode, DataNode, JobTracker, TaskTracker 5个任务,Hadoop 进程以分离的 Java 进程来运行。
修改core-site.xml
是Hadoop在运行时候的核心文件,配置集群全局参数,定义系统级别的参数,如DFS,URL,Hadoop的临时文件目录等。
Hadoop默认启动的时候使用的是系统下的 /temp 目录下,但是在每一次重启的时候系统都会将其自动清空 ,如果没有临时的储存目录有可能会在下一次启动Hadoop的时候出现问题.
内容如下
1 | <configuraion> |
hadoop.tmp.dir–临时文件夹
fs.defaultFS–文件系统主机和端口
修改hdfs-site.xml
进行HDFS 分布式储存的配置,修改hdfs的参数,如节点存放位置,文件读取权限等。
内容如下
1 | <configuration> |
dfs.replication–Hadoop的备份系数,默认是3。指每个block在hadoop集群中有几份,系数越高,冗余性越好,占用存储也越多。因为这里是伪分布式环境只有一个节点,所以这里设置为1。
dfs.namenode.name.dir–定义dfs的名称节点在本地文件系统的位置。
dfs.datanode.data.dir–定义dfs的数据节点存储数据块时,存储在在本地文件系统的位置。
修改mapred-site.xml
修改MapReduce参数,包括JobHistory Server和应用程序参数两个部分,如reduce任务默认个数,任务能够使用的内存默认上下限等。
先将文件重新命名
1 | mv mapred-site.xml.template mapred-site.xml |
修改内容如下:
1 | <configuration> |
mapreduce.framework.name–取值local,classic,yarn中一个,选择yarn则用yarn集群来实现资源的分配。
mapreduce.jobhistory.address–历史服务器的地址和端口,通过历史服务器查看已经完成的Mapreduce的作业记录。
mapreduce.jobhistory.webapp.address–历史服务器的web应用的地址和端口
修改yarn-site.xml
集群系统资源管理参数,配置RescourceManager,NodeManager的通信端口,web监控端口等。
1 | <configuration> |
yarn.nodemanager.aux-services–自定义一些服务,配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法(?)。
yarn.resourcemanager.hostname–指定了Resourcemanager运行在哪个节点上(本级ip)。
YARN的Web页面:YARN的Web客户端端口号是8088,通过http://localhost:8088/可以查看。
运行Hadoop
初始化HDFS系统
1 | hdfs namenode -format |
出现如下截图即成功
开启NameNode和DataNode守护进程
1 | start-dfs.sh |
或启动所有节点,包括NameNode,SecondaryNameNode, JobTracker, TaskTracker, DataNode。
1 | start-all.sh |
启动后用jps命令查看当前运行节点。
1 | jiaxuehui@ubuntu:~/hadoop/hadoop-2.9.2/etc/hadoop$ jps |
如果出现问题,去log里查看,一般是主机名,端口号占用的问题。
web访问
YARN的Web客户端:启动yarn可以用8088端口查看resourceManager提供的web服务,可以通过localhost:8088在浏览器查看集群的各类信息,查看任务的运行情况。
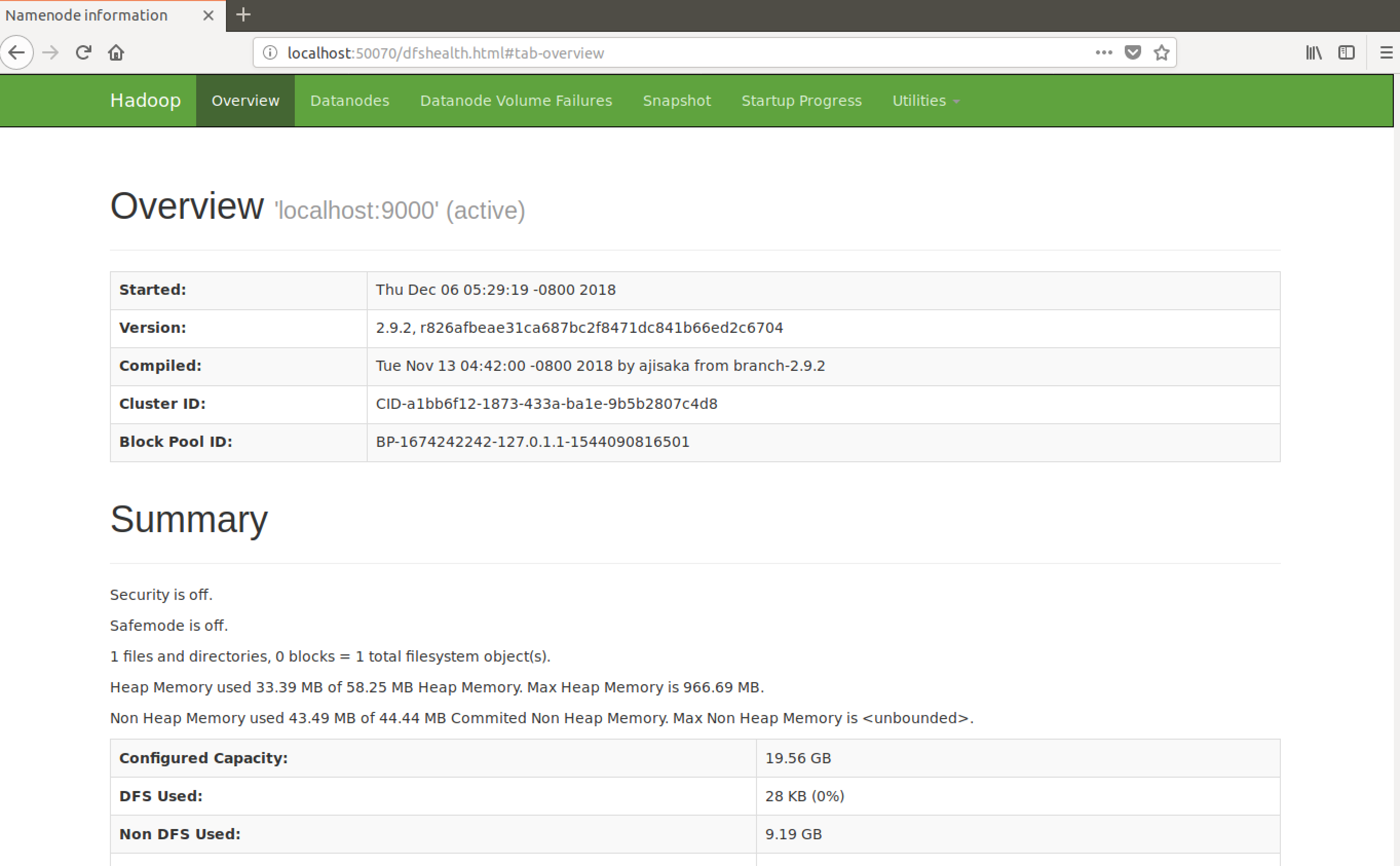
访问50070端口查看hdfs的管理界面
运行worldCount
worldCount是hadoop提供的例子,计算一个文件中单词出现的次数,在./share/hadoop/mapreduce/mapreduce.hadoop-mapreduce-examples-2.9.2.jar,运行来体验刚搭建好的环境。
先创建input文件:在本地创建一个文档vim ~/wordCountTest.txt,我拿该篇博客作为内容,粘贴进去。
在hdfs新建文件夹用来放文档,但是出现如下warning
1 | jiaxuehui@ubuntu:~$ hdfs dfs -mkdir /wordCountTest |
将如下路径添加到环境变量,就没有warning 了
1 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native" |
查看新建的目录
1 | jiaxuehui@ubuntu:~$ hdfs dfs -ls / |
将本地words文档上传到test目录中,查看
1 | jiaxuehui@ubuntu:~$ hdfs dfs -put ~/wordCountTest.txt /wordCountTest |
运行wordcount
1 | jiaxuehui@ubuntu:~$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce- |
正在运行,输出如下: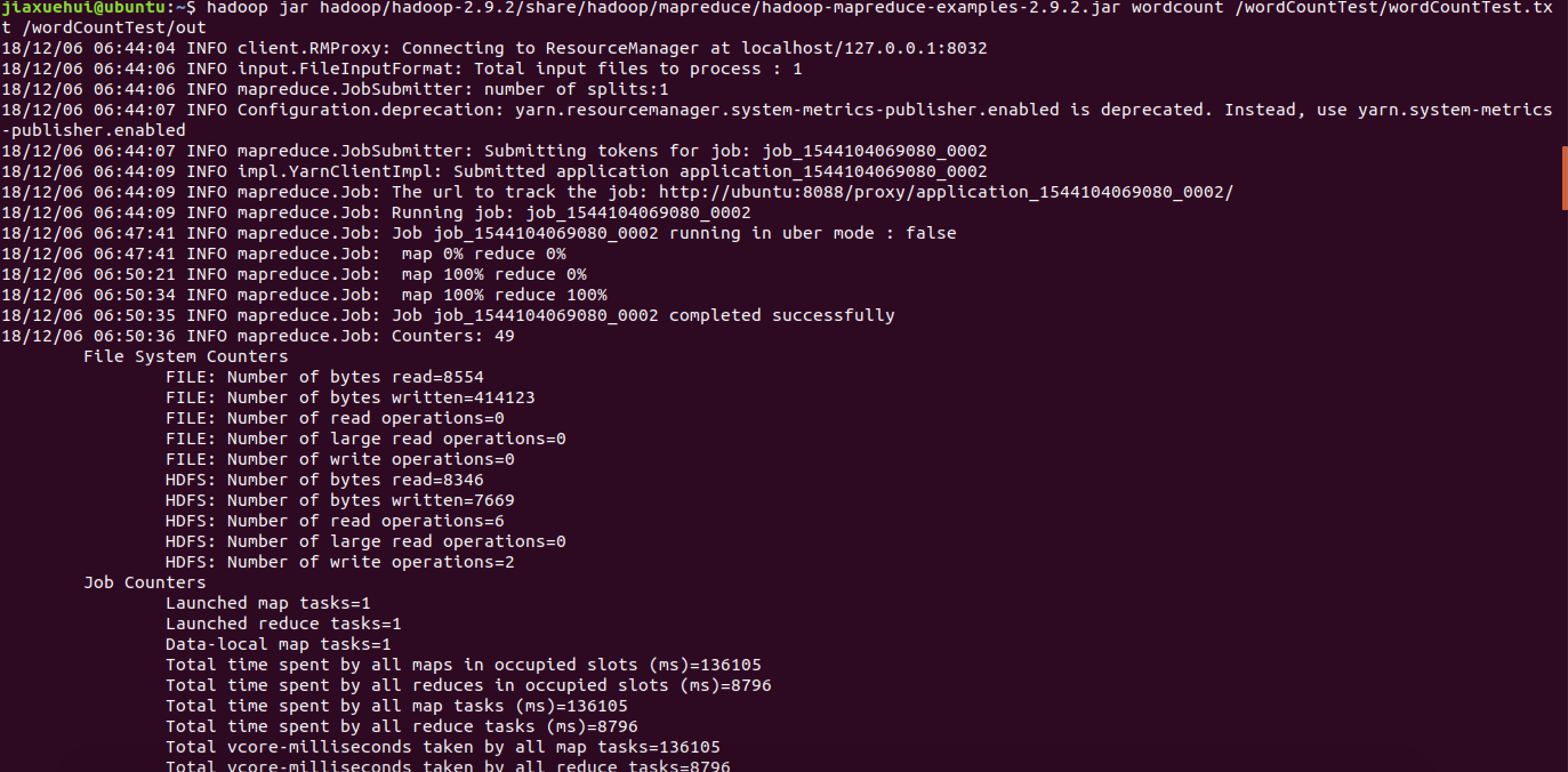
运行结束,输出文件输出到指定位置
1 | jiaxuehui@ubuntu:~$ hdfs dfs -ls /wordCountTest/out |
查看结果:已经将文章中的词汇作出统计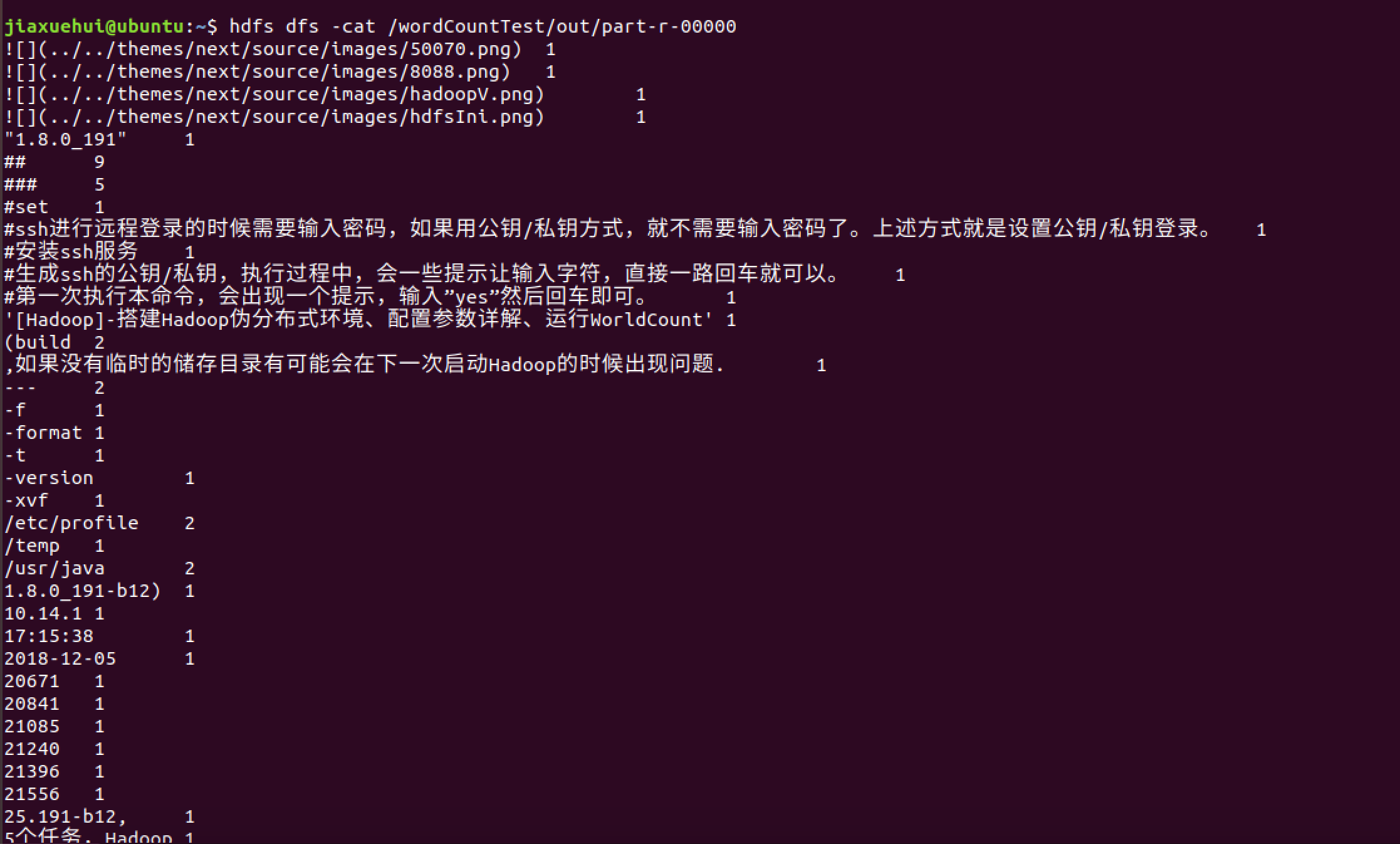
这时再查看yarn的web工具,已经有了一个已完成的任务
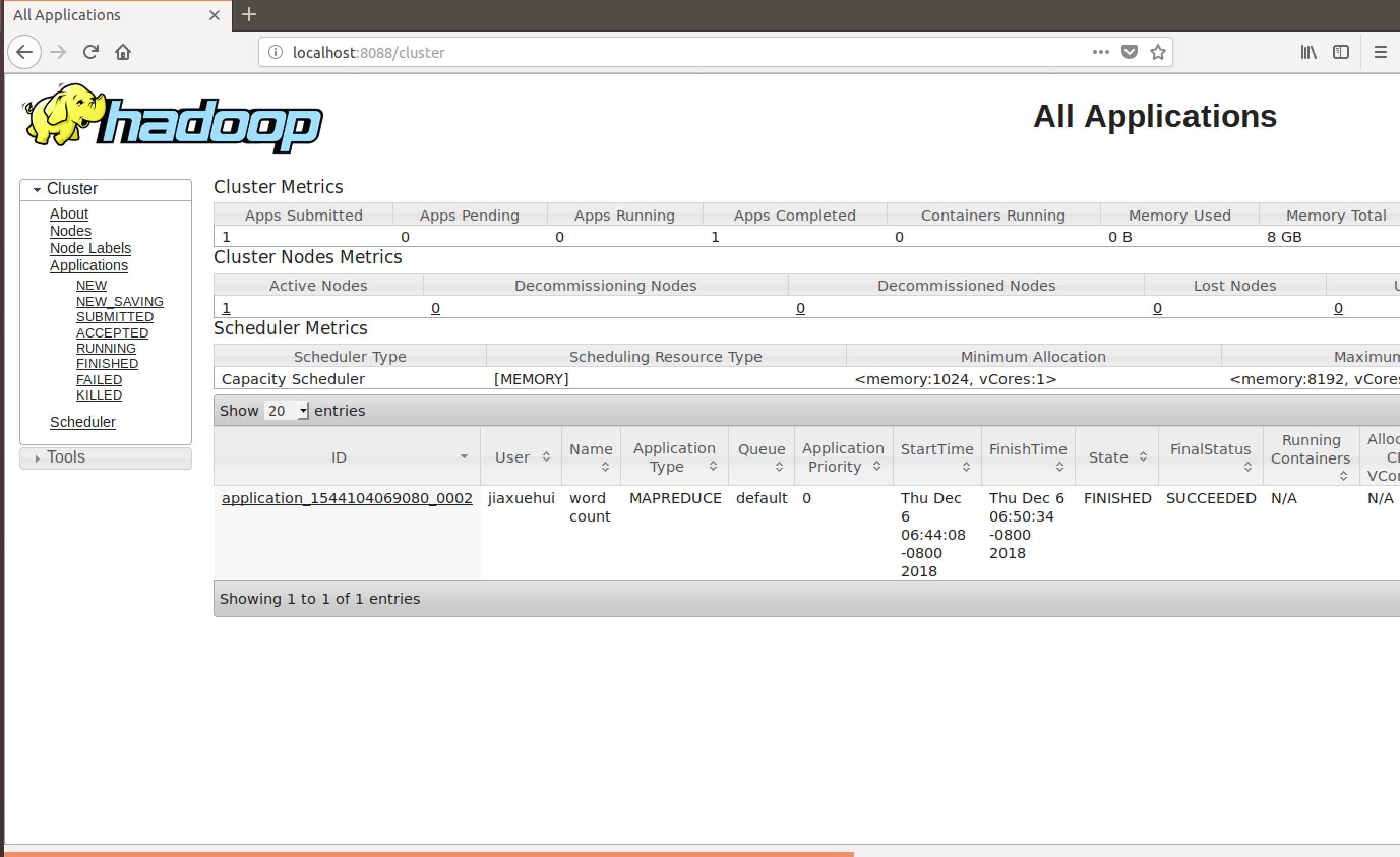
至此运行结束。只是一个初体验,验证一下环境搭建成功~~
参考源:
hadoop参数配置详解:https://zhuanlan.zhihu.com/p/25472769
hadoop入门指南:https://www.kancloud.cn/fymod/hadoop/596103